Mining Company - Data Integration Tool
Background
The Company has mining operations spread across 7 countries.
Problem
Each mine operation stores data in a combination of standard and bespoke data sources. The Company would like to integrate data across all of its operations in a single data lake and perform analytics on their data.
Their current time to integrate new data sources ranges from weeks to months, depending on the connector availability. Each integration is hand-coded using a range of bespoke SSIS, C# and Python scripts. There is no standardisation of data integration patterns.
Solution
Data integration platform
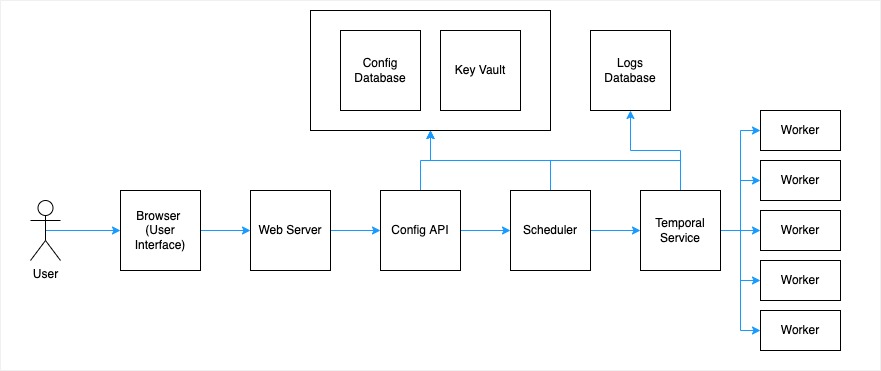
User Interface: An easy to use graphical interface to configure new sources, destinations and sync pipelines. The UI was built using Bootstrap, jQuery, ASP.NET Core Razor PagesWeb Server: The web server utilised C#/.NET Core and was hosted on Azure Web Service. The web server communicated to the API layer.Config API: The Config API was written using a combination of C# logic and SQL Stored Procedures that executed on the Config Database. All operations such as creating sources, destinations and sync pipelines are configured using the API.Config database, Key vault: The config API writes sync tasks configuration (source, destination, sync details e.g. sync schedule, data type/column mappings) to the config database. All connection string and secrets are stored in Azure Key Vault.Scheduler: The scheduler takes any tasks from the Config Database and creates a new task instance for execution. The scheduler utilised is Azure Data Factory’s scheduler.Temporal Service: The temporal service is an instance of a task and executes on Azure Data Factory Pipelines (cloud). The temporal services writes logs to theLogs databaseat each step of the task execution.Worker: The worker executes on Azure Virtual Machines which are configured as an Azure Data Factory Integration Runtime (IR) High Availability Cluster. Multiple executions can occur in parallel to distribute workload amongst the workers.Logs Database: A logs database stores the execution logs so that execution intemediary and final statuses are captured. A Power BI Report visualises task execution statuses stored in the logs database.- The Company’s data sources are hosted on-premise and Azure ExpressRoute is utilised to achieve connectivity from Azure Cloud to on-premise. A private VNet is created to ensure data ingested sits behind a firewall at all times.
- The open-sourced solution can be found here: https://github.com/jonathanneo/AzureDataPlatform
- Note: This solution was built prior to the release of airbyte. I recommend using airbyte today and not re-inventing the wheel. Or fivetran if you are after a SaaS solution.
Outcome
- Data integration (source to destination) time was reduced from months to a matter of days (including testing).
- Product Owner:
Jonathan has been a great team player with very strong technical capabilities in the Azure data space which has helped me personally and the data team to quickly understand and help deploy the solution within weeks. He brings vast expertise and knowhow in data engineering, analytics and visualization area which he has clearly showcased in the Solution architecture and data modelling sessions we’ve had with our company and Microsoft. Jonathan exhibited clear understanding of the requirements and was quick to take suggestions and feedback to address some of the challenges in an effective manner where needed.
- The data integration solution received a score of 77% from Microsoft (Perth).